俺去l啦 想维链?想维树?华为诺亚:当今到了想维丛林技术

OpenAI 接连发布 o1 和 o3 模子俺去l啦,大模子的高阶推理才智正在迎来爆发式增强。在预本质 Scaling law “撞墙” 的配景下,探寻新的 Scaling law 成为业界怜惜的热门。高阶推理才智有望开启新的 Scaling law,为大模子的发展注入新的活力。
近日,华为诺亚方舟实验室的盘考东谈主员建议了一个名为想维丛林 “Forest-of-Thought”(FoT)的全新大模子高阶推理框架,它通过在推理时膨胀蓄意领域,显耀擢升了 LLM 的高阶推理才智。

论文连气儿:https://arxiv.org/abs/2412.09078
名堂连气儿:https://github.com/iamhankai/Forest-of-Thought
LLM 的推理逆境
尽管 LLM 在多种谈话任务上阐扬出色,但在惩处复杂推理问题时,它们往往堕入逆境。以数常识题为例,LLM 可能会在剖释问题的经过中忽略枢纽细节或在中间措施中出错,导致最终谜底乌有;频频完成一条推理旅途后,大模子频频不会再行扫视其他可能的措施,这种穷乏再行评估的才智使得惩处决策无法全面应付复杂的问题。比拟之下,东谈主类在处理复杂问题时,会从不同角度反复想考和考证,以确保谜底的准确性。
想维丛林 FoT 措施先容
图 1 中的 FoT 框架通过整合多个推理树,行使集体决策的上风来惩处复杂的逻辑推理任务。它接受寥落激活政策,礼聘最相干的推理旅途,从而提高模子的遵循和准确性。此外,FoT 还引入了动态自校正政策,使模子不详在推理经过中及时识别和调动乌有,并从畴前的乌有中学习。共鸣率领决策政策也被纳入其中,以优化正确性和蓄意资源的使用。
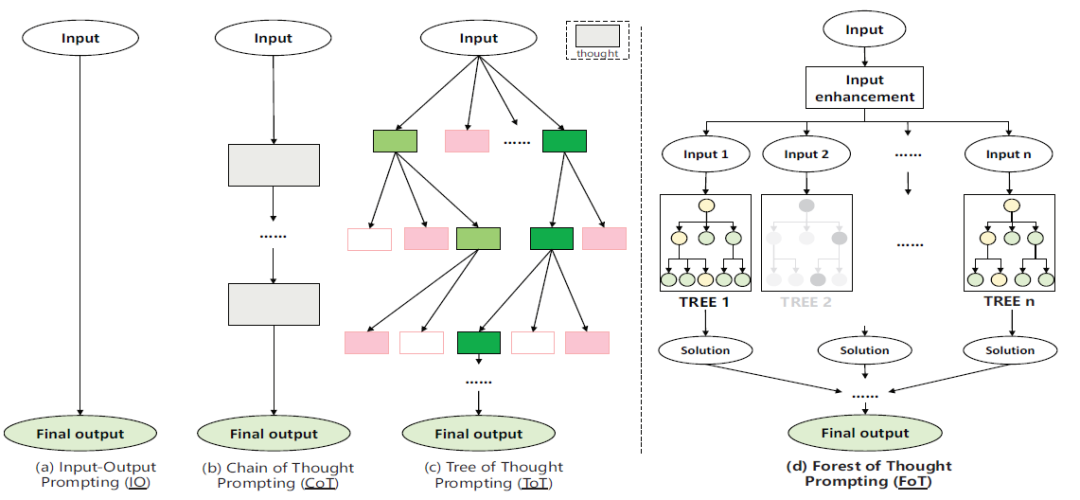
图 1 想维丛林 FoT
寥落激活政策
在 FoT 的推理经过中,并不是通盘的推理树或树中的每个节点齐会被蓄意,而是只礼聘最相干的推理树或节点进行蓄意。这种措施不仅提高了遵循,还通过礼聘最相干的推理旅途来提高模子的准确性。通过寥落激活,FoT 不详过滤掉每个推理树的激活,确保只好某些推理树的旅途被 “激活” 用于推理。
动态自校正政策
为了提高每个推理树给出正确谜底的概率,FoT 引入了动态自校正政策。关于推理树的开始限度,自校正政策会评估其正确性和灵验性,并在每个推理措施完成后分拨相应的分数。一朝某个措施的分数低于预设阈值,政策会自动触发校正机制。该机制率先转头和分析畴前的失败案例,识别低分和常见乌有格局的原因,然后尝试调动乌有并优化推理地点。通过这种从历史中学习和及时校正的机制,模子不仅幸免了在调换问题上重叠犯错,还能更速即、更准确地找到惩处新问题的灵验措施。

图 2 动态自校正政策
共鸣率领决策政策
为了惩处复杂的数常识题,FoT 想象了共鸣率领巨匠决策(CGED)政策,以确保最终谜底的高准确性和可靠性。CGED 措施聚会了集体智谋和巨匠判断,率领推理经过从基于共鸣的决策转向巨匠评估。在 FoT 措施中,每个平定树通过其特有的推理旅途生成一个或多个可能的谜底。子树会对候选谜底进行投票,选出获取最多补助的谜底。若是无法达成共鸣,数学巨匠将评估推理经过并礼聘最终谜底,以确保其准确性和灵验性。
实验限度
盘考东谈主员在多个 LLM 推理基准测试中评估了 FoT 措施,包括 24 点游戏、GSM8K 和 MATH 数据集,使用了多个开源 LLM 模子,包括 Llama3-8B,Mistral-7B 和 GLM-4-9B。
24 点游戏
24 点游戏的认识是使用给定的四个数字各一次,通过加、减、乘、除和括号构造一个算术抒发式,使其限度为 24。表 1 中的实验限度标明,当推理树的数目从 2 加多到 4 时,FoT 的准确率提高了 14%,裸表示显耀的推感性能擢升。比拟之下,仅加多单个树的叶子节点数目的 ToT 措施遭遇了性能瓶颈,进一步加多叶子节点数目并未带来显耀的性能擢升。这标明 FoT 通过多棵树提供的推理旅途各样性比单纯加多单个树的复杂性更灵验,突显了 FoT 框架在兑现可膨胀和高效推理改进方面的上风。
暴力强奸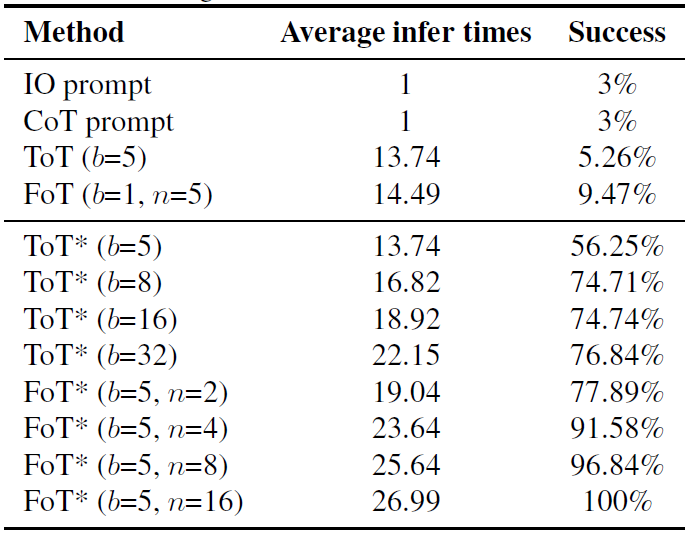
表 1 24 点游戏,Llama3-8B 基模子,b 是叶子节点数目,n 是树数目
GSM8K 基准测试
盘考东谈主员在 GSM8K 数据集上评估了 FoT 在不同基模子上的性能。图 3 中的实验限度标明,基于不同的大谈话模子 Llama3-8B,Mistral-7B 和 GLM-4-9B,齐存在访佛的 scaling law:FoT 中的树数目越多,带来的准确率擢升越显耀。
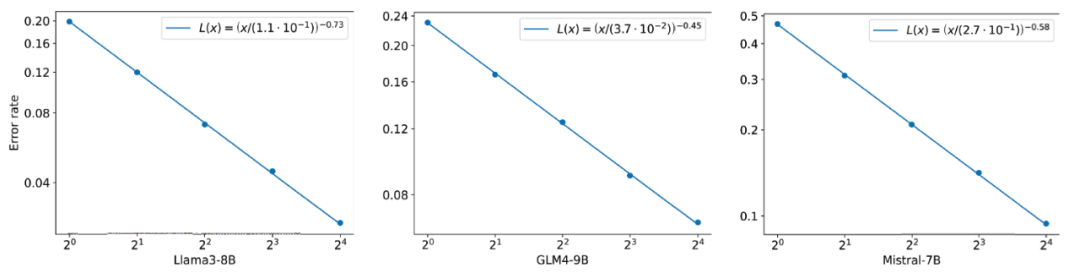
图 3 FoT 在不同基模子的性能
MATH 基准测试
在 MATH 数据集上,FoT 算法在不同复杂度级别的问题上均展现出一致的性能擢升。如表 2 所示,从最浅近的 level1 到最具挑战性的 level5,FoT(n=4)的准确率比 MCTSr 提高了约 10%。这种一致的擢升突显了 FoT 措施在处理简易单到复杂问题的灵验性。
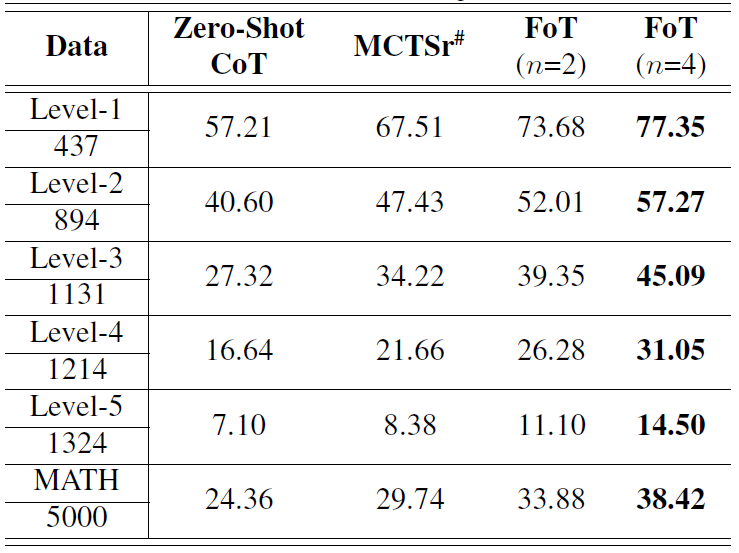
表 2 FoT 在 MATH 数据集上的性能
FoT 的平凡应用远景
FoT 框架不仅在表面上具有创新性,况兼在本色应用中也具有平凡的远景。它不错匡助 LLM 在数学、逻辑、金融、医疗和法律等需要复杂推理的领域中更好地施展作用。举例,在金融领域,FoT 不错用于风险评估和投资决策分析;在医疗领域,它不错辅助大夫进行疾病会诊和诊疗决策制定;在法律领域,FoT 不错用于案例分析和法律推理。此外,FoT 还不错与现存的 LLM 采鸠合,擢升其在法律、教悔、科研等领域的应用后果,为用户提供愈加智能、准确的工作。
结语
想维丛林 Forest-of-Thought 框架的建议,为 LLM 的推理才智擢升提供了一条新的旅途。它通过多旅途探索和动态激活推理旅途的结构化框架,灵验惩处了现存 LLM 推理范式中的枢纽局限。FoT 不仅提高了模子在复杂任务中的问题惩处才智俺去l啦,还生成了各样化的推理限度,无需依赖反向传播或微调。跟着大模子在平日使命和生存的抵制浸透,FoT 有望在更多的应用场景中施展坚苦作用,股东大模子向更智能、更高效的地点发展。